

mobile app performance
Observability teams often ask why we don’t show monolithic traces for issues like slow startups. While they theoretically reveal all services involved, they’re hard to interpret, and distract from what’s critical: the mobile experience context.
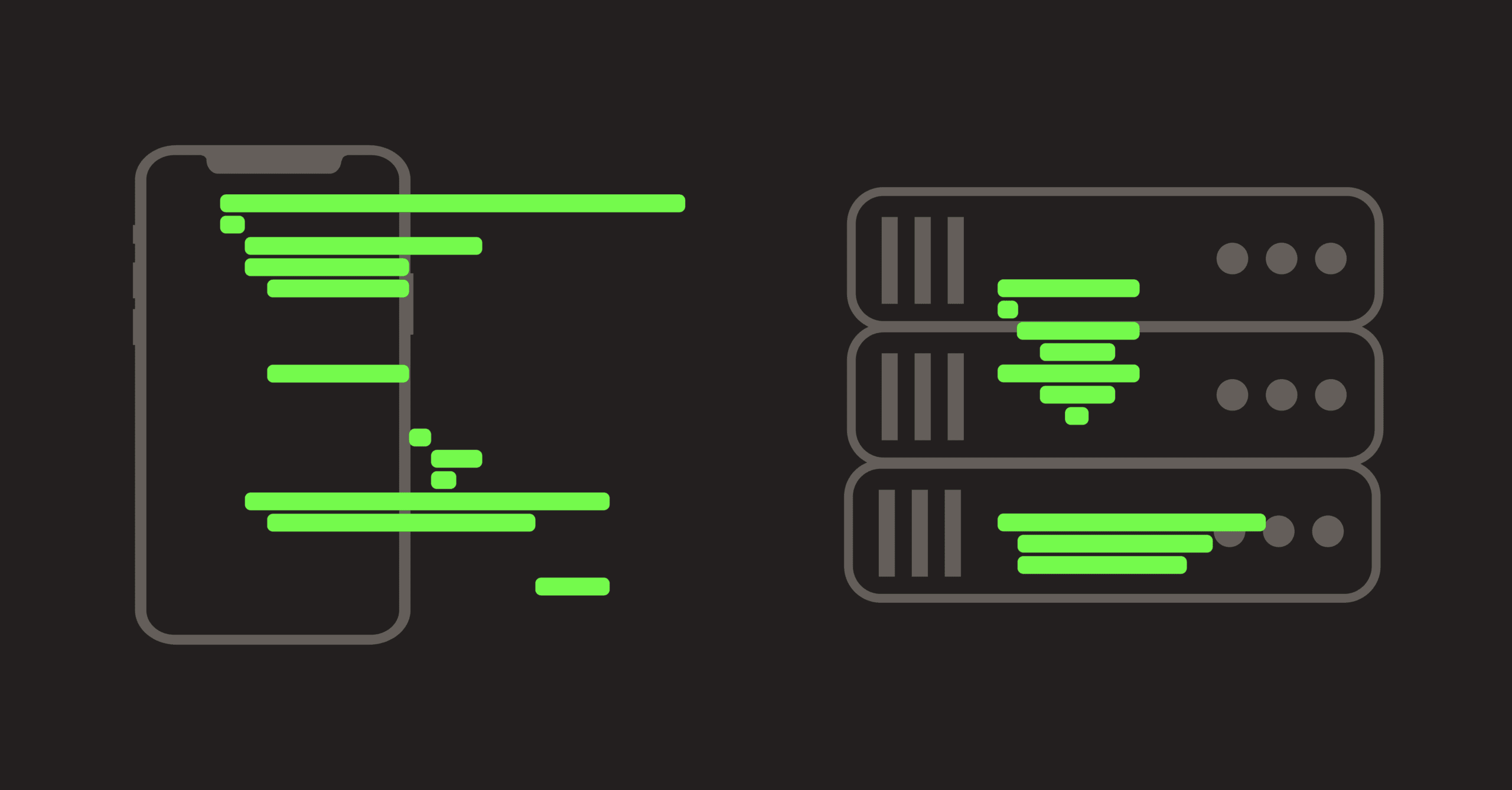
We are frequently asked by observability teams why using tracing to measure mobile app performance differs from using distributed tracing to measure backend services. They want to connect a mobile trace to its corresponding distributed trace and see everything in a single, monolithic trace.
After all, isn’t end-to-end visibility just seeing all the frontend spans alongside all the backend spans?
Well, not really.
In backend observability, distributed traces shine at showing the path of a single request across multiple services, containers, and nodes.
However, that same approach falls short when it comes to mobile apps. The concept you need instead is the mobile performance trace — a trace built around the user’s experience on a single device, not the backend service topology.
In this post, we’ll cover why mobile observability requires a different approach to tracing than backend observability.
A distributed trace answers the question, “How does one request move through my distributed system, and where is it slowing down?”
Characteristics:
A mobile performance trace starts and ends on the user’s device and measures all relevant activity for a specific user action, such as “load the shopping cart” or “post a photo.”
Characteristics:
A common request from observability teams is, “If I have a mobile performance trace, why can’t I see all spans in one giant waterfall?”
Reason: Because a mobile performance trace can involve multiple distributed traces, one for each backend request.

Example: Loading the cart might trigger:
These traces are independent in the backend. Combining them under one root span creates an unrealistic call chain, inflated durations, and misleading causal relationships. In other words, super-long unrelated traces affect short traces from other services.
It also makes it really hard for each team to get visibility into their own stuff. A team that owns their own vertical product can’t focus on their piece and understand if there is a problem.

The second image above illustrates that the distributed trace /api/recommendations is affecting the entire operation. Showing details about the remaining services /api/cart and /api/catalog only adds noise to the analysis.
To analyze a mobile performance trace, it’s enough to have the client-side network request, which happens to be the root span of a distributed trace in the backend observability platform. We can think of the client-side network request as a “pointer” to a distributed trace.

Backend observability
Mobile observability
A note on “end-to-end observability”
The phrase end-to-end observability is often used in backend discussions to mean following a request from the first hop to the last hop in a distributed system.
In mobile, however, the same phrase can be misleading — it might suggest a single trace ID linking everything from the tap to all backend responses, which is not how mobile performance traces work. Instead, mobile end-to-end visibility means combining:
Analogy:
traceparent is only injected in the network request spanIn mobile observability, the traceparent header is injected only into the network request span — not into the entire mobile performance trace.
Why?
trace_id that links unrelated API calls in the backend. This behavior is defined by the W3C trace context specification, which defines to attach the header to outbound network requests for distributed traces.Waterfall visualizations in backend tools are designed for request-response analysis.
For mobile actions (human-driven, async, multi-threaded), merging all spans leads to:
Better: Keep distributed traces for backend RCA, and use mobile performance traces for user experience RCA.
Get started today with 1 million free user sessions.
Get started free
