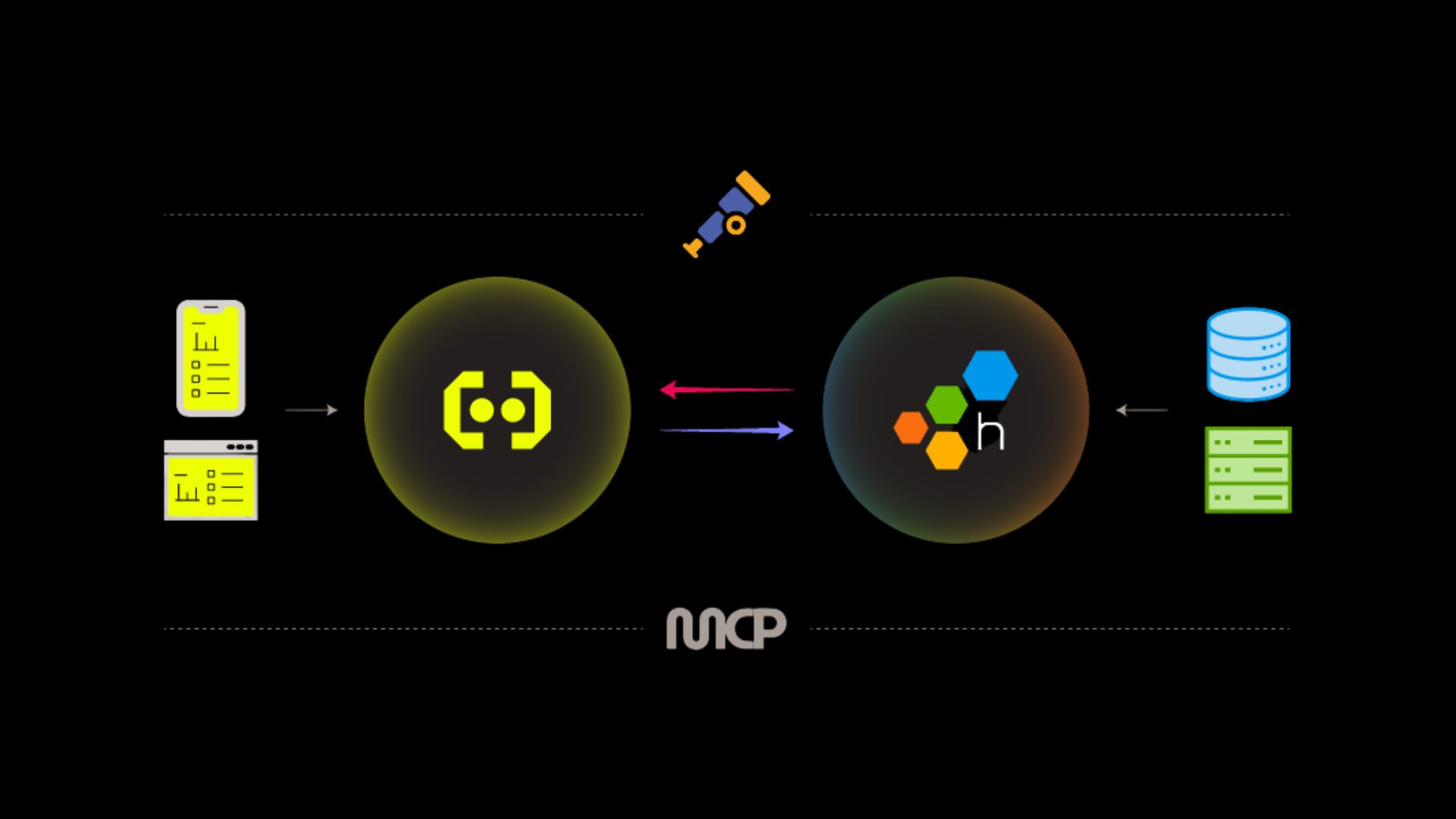
Here’s the big news: We’ve launched a strategic partnership with Honeycomb to bring web and mobile RUM to the industry-leading services and infrastructure reliability platform our friends at Honeycomb are building.
The reasons go deeper than the product. We built Embrace on OpenTelemetry because we believe the future of observability is open, composable, and high-fidelity. We’ve always believed that frontend and mobile performance and reliability aren’t a separate discipline from observability, they’re just the part of the system that legacy platforms didn’t reach. Honeycomb has pioneered the same philosophy we’ve been building on at Embrace on the backend: that high-cardinality, context-rich data lets engineering teams understand systems in ways that weren’t previously possible.


