

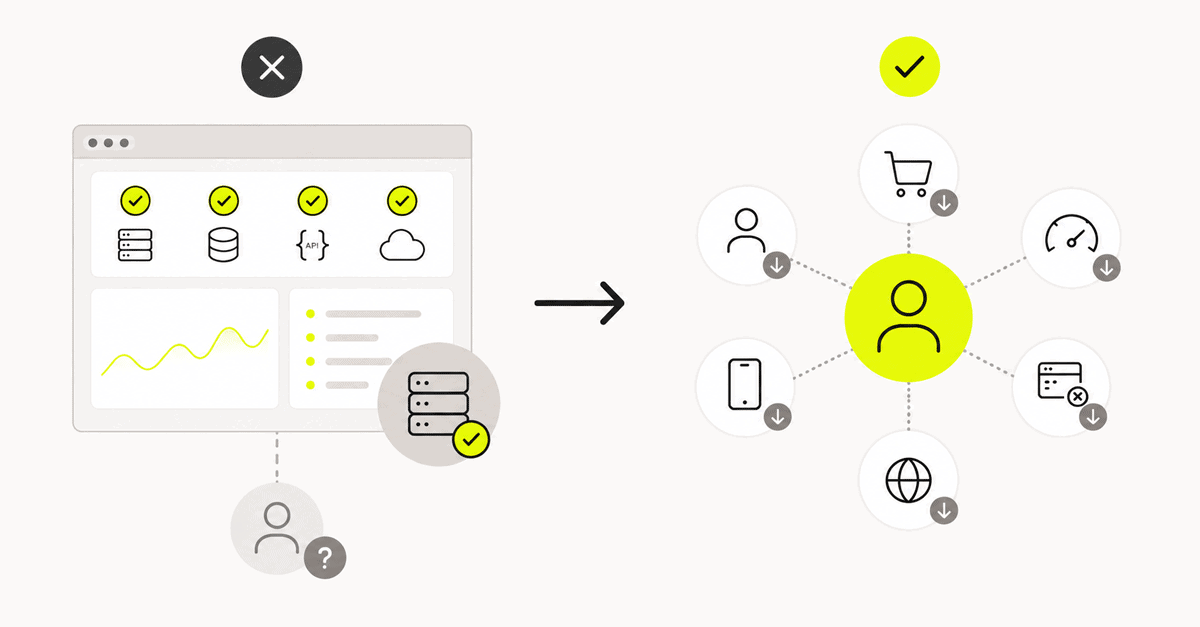
I know how that sounds coming from someone who works at an observability company. But I spent six years as an iOS engineer before this, and I remember exactly what it felt like — chasing bugs I couldn’t reproduce, staring at dashboards that said everything was fine while users were clearly hitting something, and assuming I was missing what everyone else had figured out.
I hadn’t missed anything. The tooling had a structural problem. Nobody was really talking about it directly.

